This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
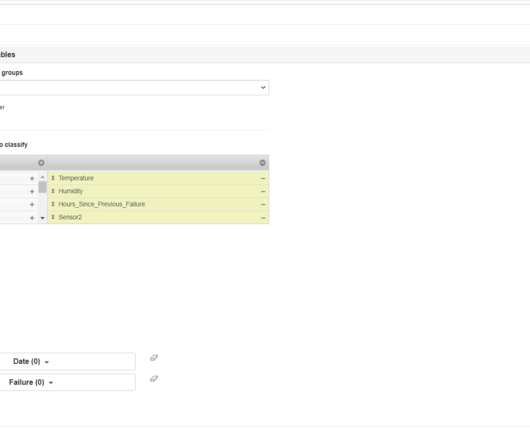
Unsupervised ML uses algorithms that draw conclusions on unlabeled datasets. As a result, unsupervised ML algorithms are more elaborate than supervised ones, since we have little to no information or the predicted outcomes. Overall, unsupervised algorithms get to the point of unspecified data bits. Source ].
Jump to: Machine Learning 101 Python Libraries and Tools Training a Machine Learning Algorithm with Python Using the Iris Flowers Dataset. Machine learning (ML) is a form of artificial intelligence (AI) that teaches computers to make predictions and recommendations and solve problems based on data. Machine Learning 101. Model training.
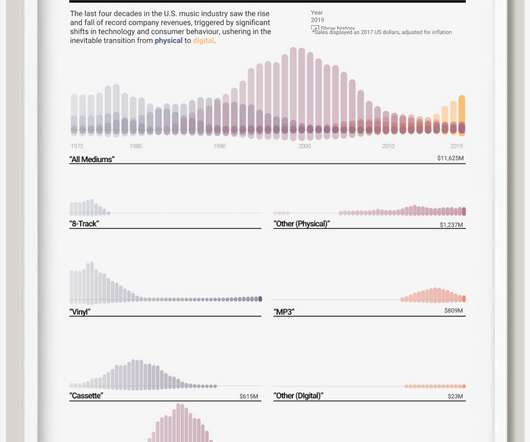
To engage your audience, whether internal or external, consider putting your data into some of today’s more popular data visualizations. The magic quadrant, often called the 2×2 matrix or the four-blocker, is great for reporting differences (i.e. opposites) or data points across two ranging scales.
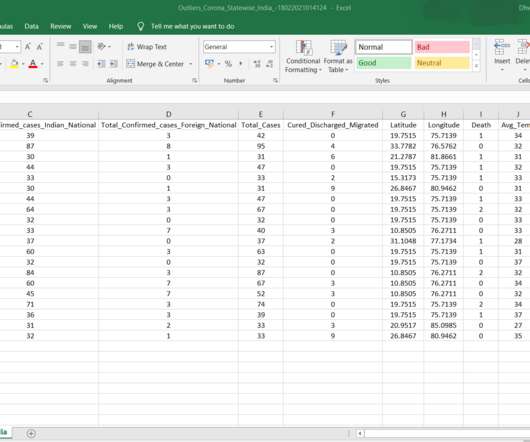
Outliers, also referred to as anomaly, exception, irregularity, deviation, oddity, arise in dataanalysis when the data records differ dramatically from the other observations. In layman’s terms, an outlier can be interpreted as any value that is numerically far-flung from most of the data points in a sample of data.
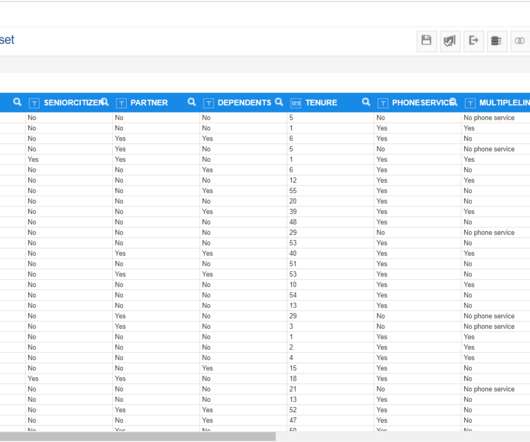
Your dataset will look as follows: Perform Elementary DataAnalysis from Dataset: From the dataset, we can see that our dataset contains many attributes/features upon which our target variable (i.e. In order to select the best category of algorithm, users need to have some basic data literacy. churn) depends.
Smarten Insight provides predictive modelling capability and auto-recommendations and auto-suggestions to simplify use and allow business users to leverage predictive algorithms without the expertise and skill of a data scientist. In order to select the best category of algorithm, users need to have some basic data literacy.
Today, most companies understand the impact of data quality on analysis and further decision-making processes and hence choose to implement a data quality management (DQM) policy, department, or techniques. According to Gartner, poor data quality is estimated to cost organizations an average of $15 million per year in losses.
We organize all of the trending information in your field so you don't have to. Join 11,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









Let's personalize your content